NLP
Before starting any of these examples, please ensure that you installed Pycaret=>2.2 in your working environment. You can use pip install pycaret==2.3.8 to install it too.
Note : Some functionalities in AutoML NLP requires an English language model. The language model is not downloaded automatically when you install Pycaret. To download the model, please type the following in your command line:
python -m spacy download en_core_web_sm
python -m textblob.download_corpora
Basic Pycaret AutoML NLP
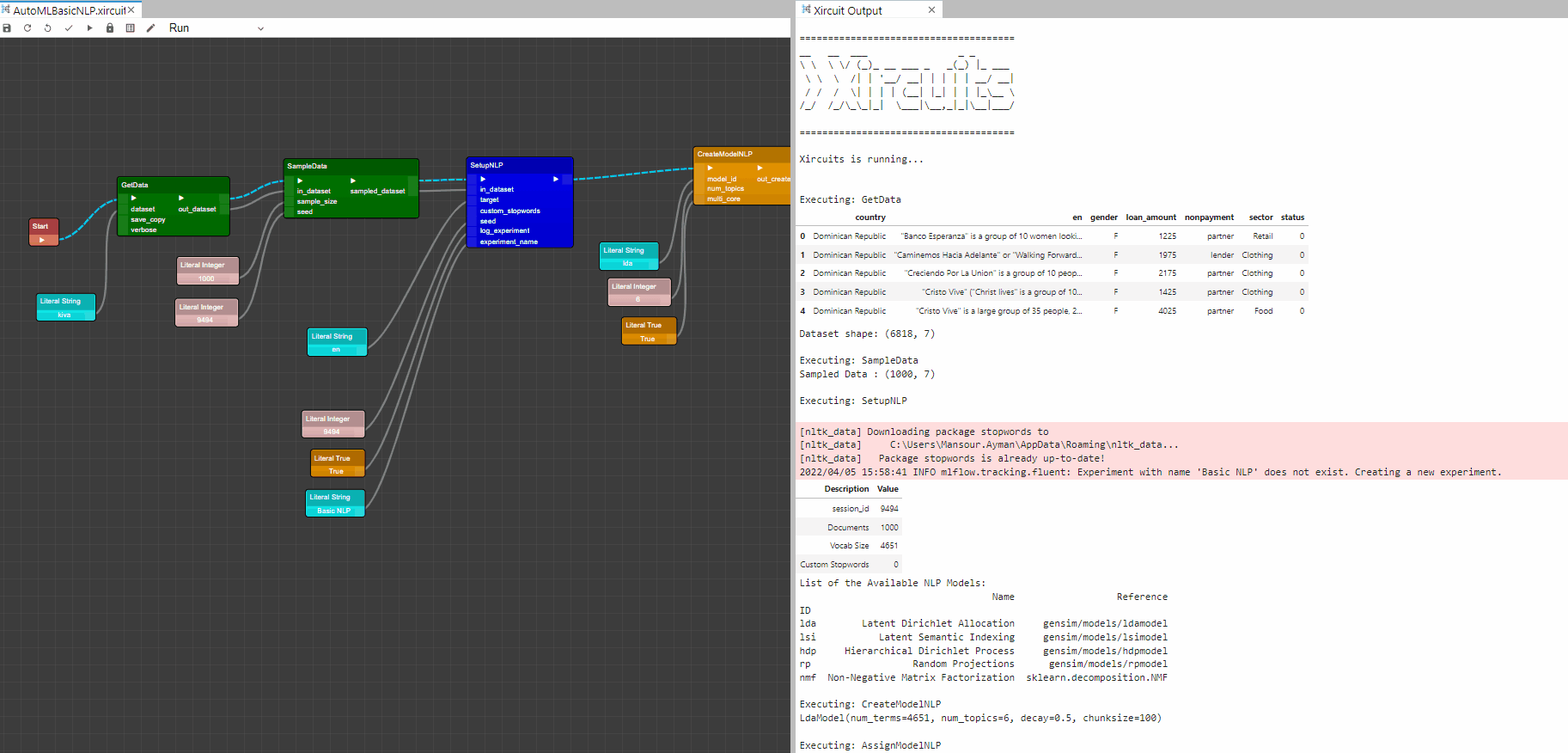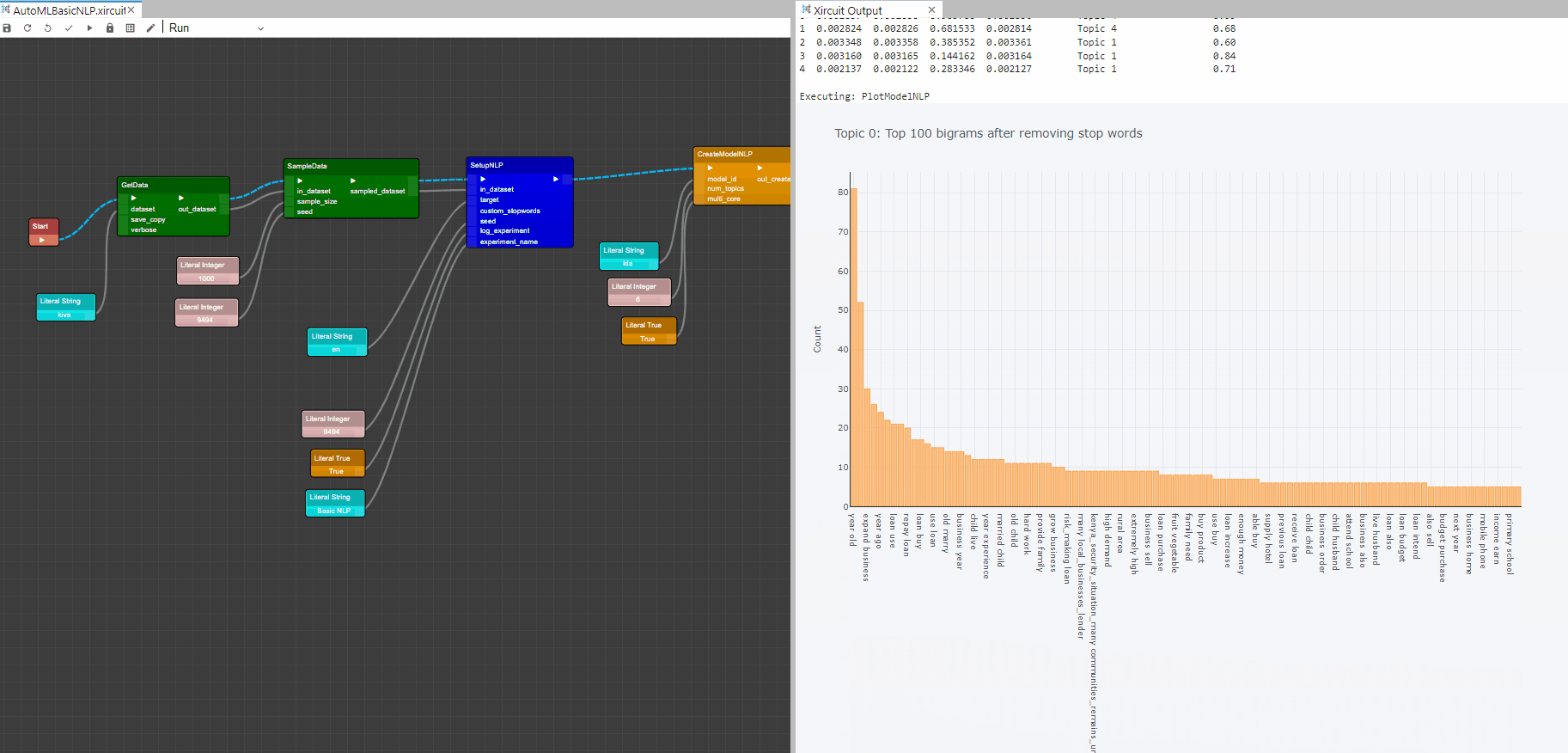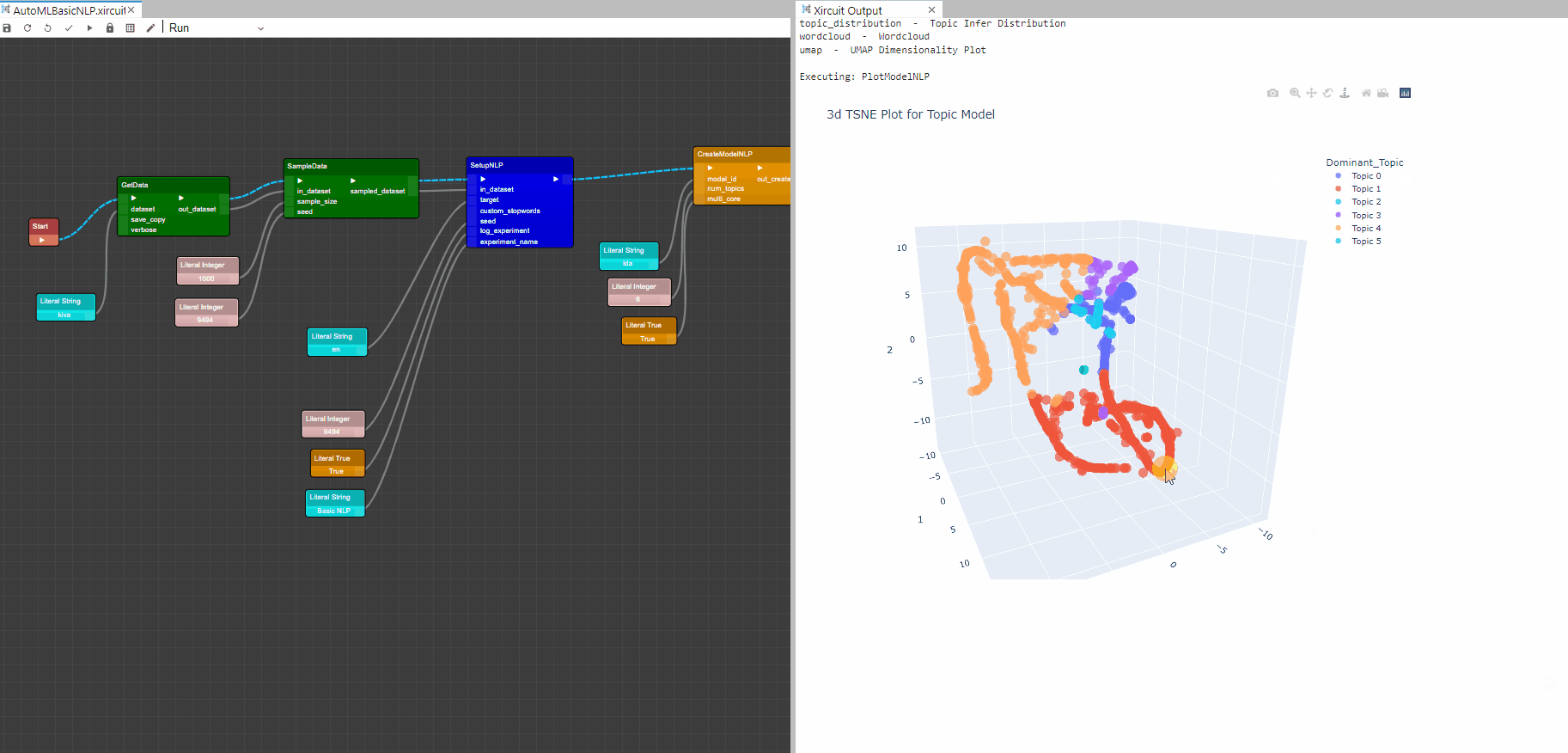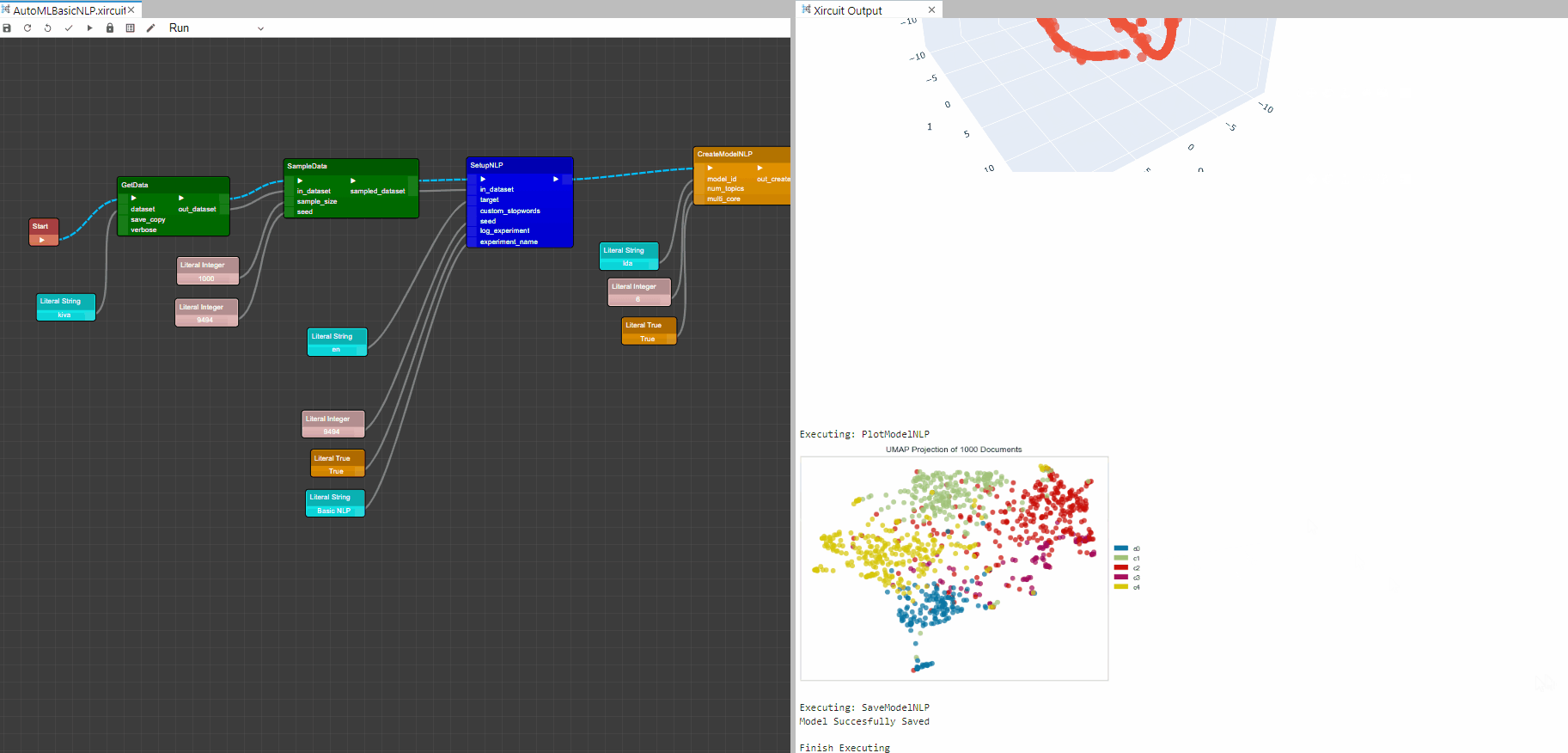
Example: AutoMLBasicNLP.xircuit
In this example, you will learn how to build a basic NLP Pycaret application that reads a tabular dataset, setup environment, create and assign NLP ML models, plot results and save the trained model.
-
To start the workflow,first you will need to get a dataset with
GetData. Here we chose the kiva dataset. Additionally,SampleDatacould be used to randomly sample certain number of row from the dataset. -
To setup the Pycaret AutoML environment you will need the
SetupNLP, This component initializes the training environment and creates the transformation pipeline.SetupNLPcomponent must be present before executing any other component. It takes one mandatory parameter in_dataset. All the other parameters are optional. -
CreateModelNLP: This component trains and evaluates the performance of a selected model. You specify the number of topics to group the words. The output of this component is a trained clustering model. -
AssignModelNLP: This function assigns topic group labels to the dataset for a given model, in this case we used the trained model fromCreateModelNLPwhich adds Dominant_Topic and Perc_Dominant_Topic columns to the dataset. Dominant_Topic in this example is the topic number with highest proportion and Perc_Dominant_Topic is the percentage of dominant topic over 1. -
PlotModelNLP: This component analyzes the performance of a trained model on the dataset. The type of the plot desired can be set in plot_type.
Plot Graphs
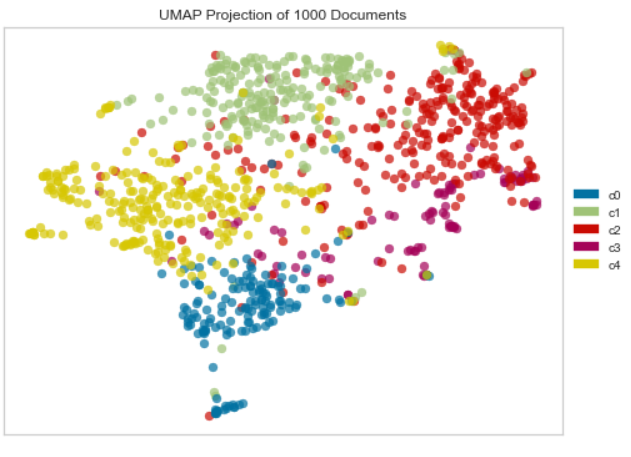
UMAP Dimensionality Plot
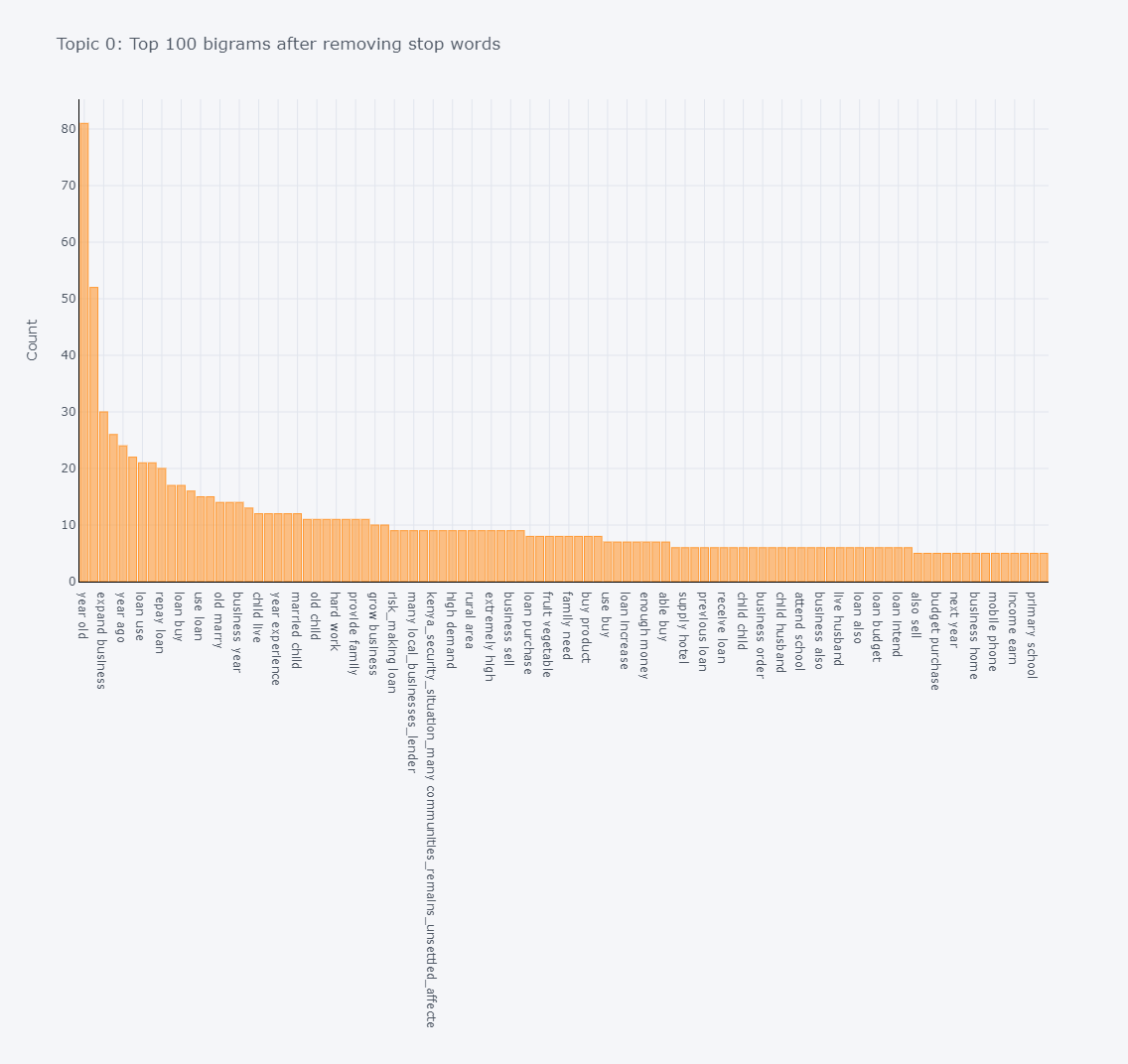
Bigram Frequency Plot
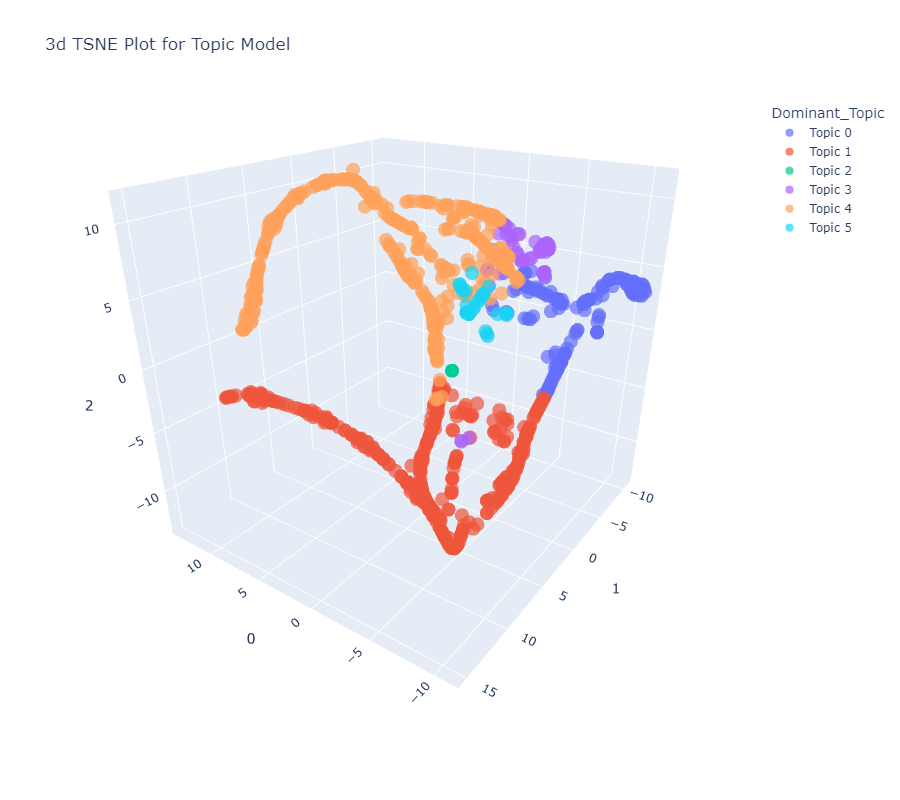
t-SNE (3d) Dimension Plot
- Lastly,
SaveModelNLP: This component saves the transformation pipeline and trained model object into the current working directory as a pickle file for later use.
Pycaret AutoML Model Tuning
Example: AutoMLTuningNLP.xircuit
In this example, you will learn how to tune the num_topics parameter in NLP model.
-
As with the previous example, you would start with a
GetDataandSampleData. -
In this example we excluded some common words from the model, this done by passing a list of the excluded words to the custom_stopwords in the
SetupNLPcomponent. -
Next, we created a basic Latent Dirichlet Allocation model with 4 topics using the
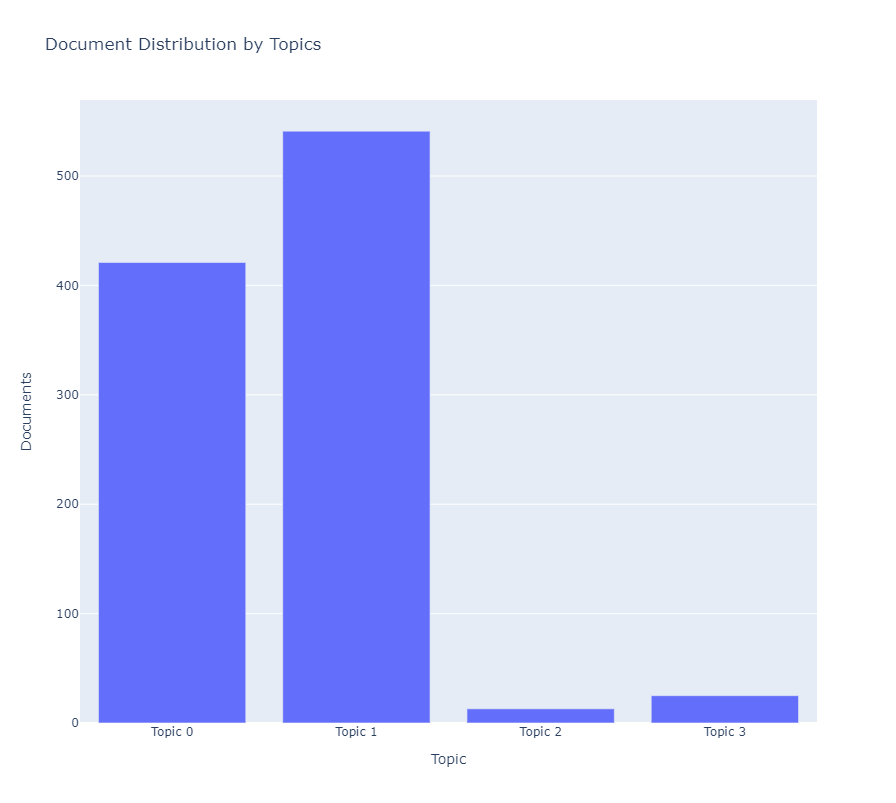
CreateModelNLPcomponent and plot the Word Distribution Plot using thePlotModelNLP.
Plot Graphs
Word Distribution Plot
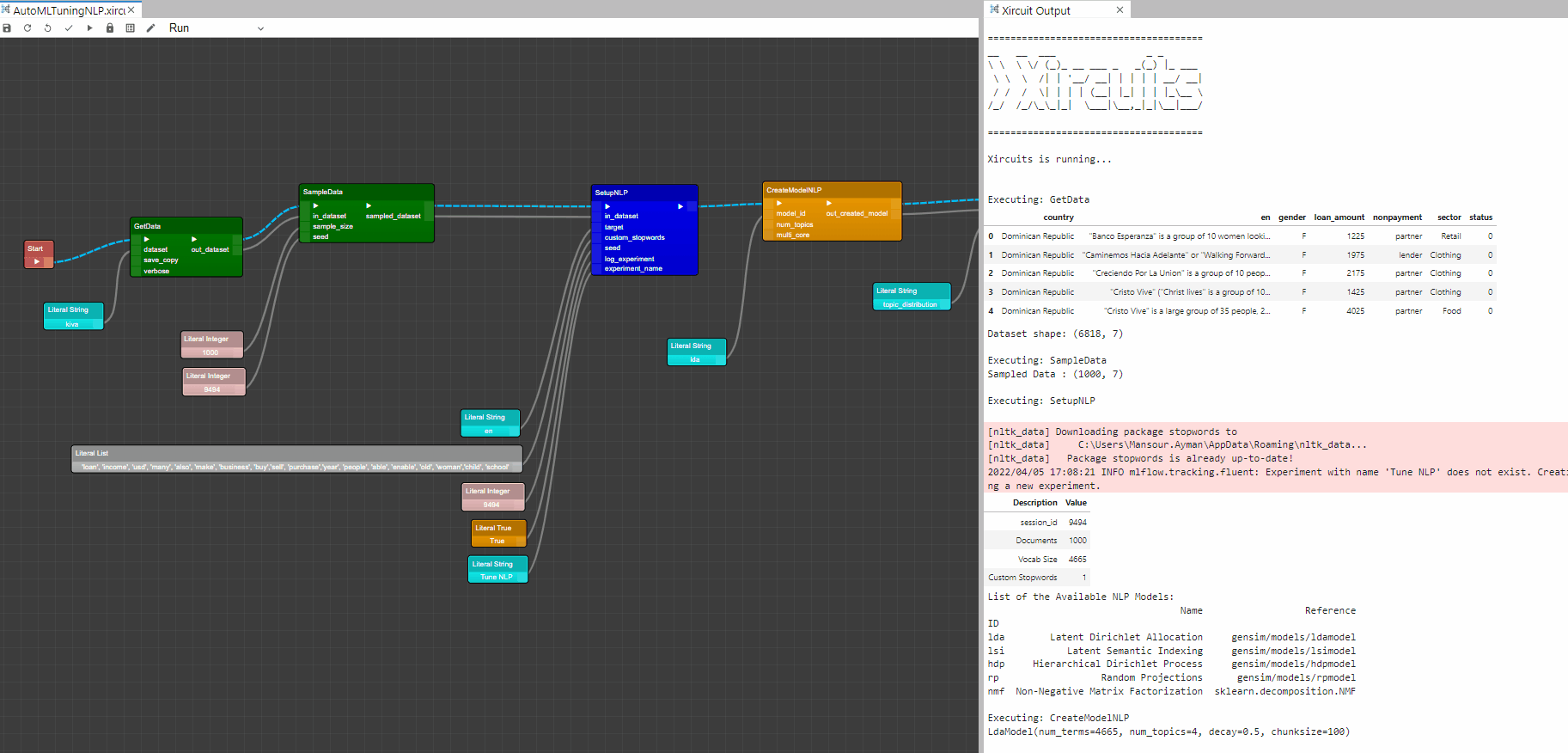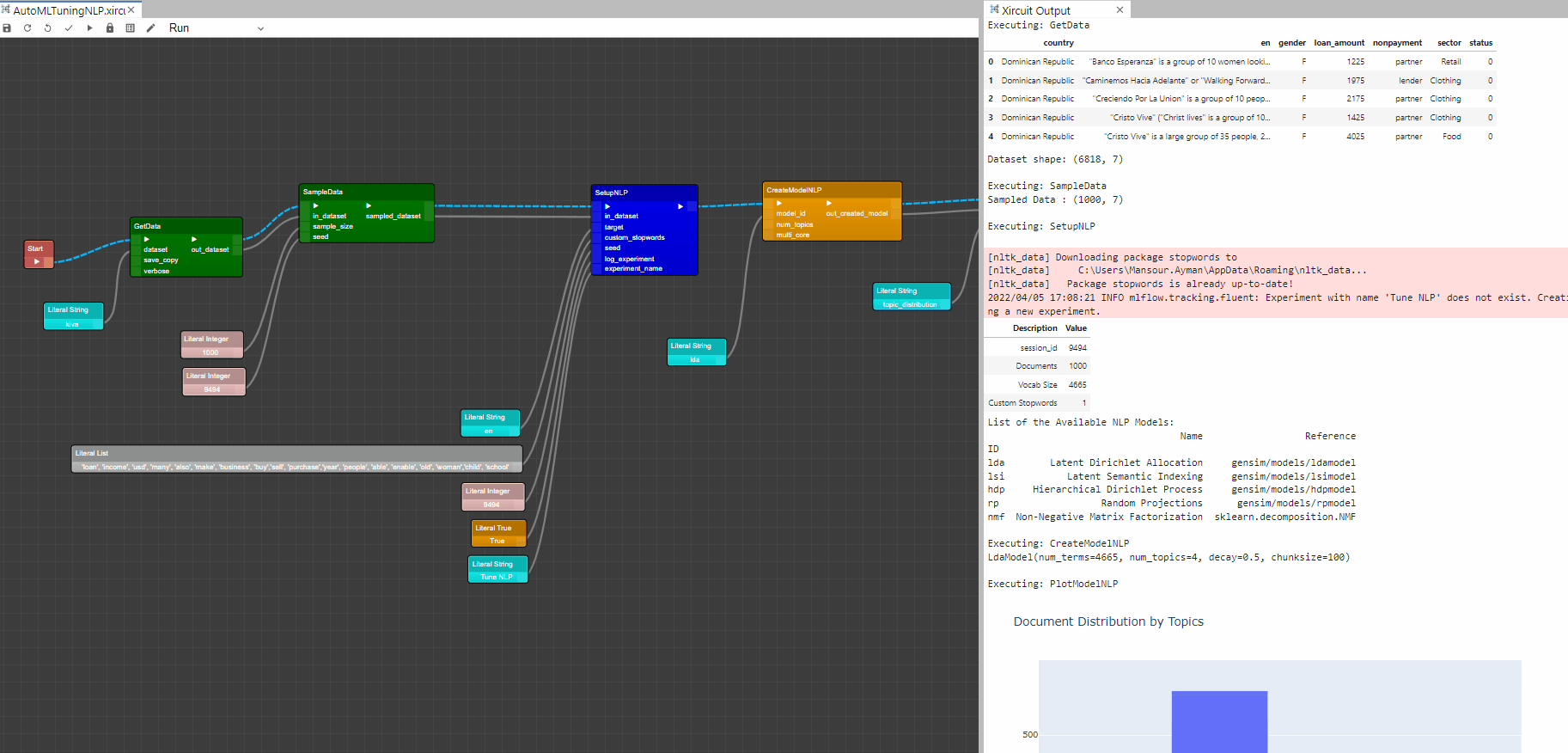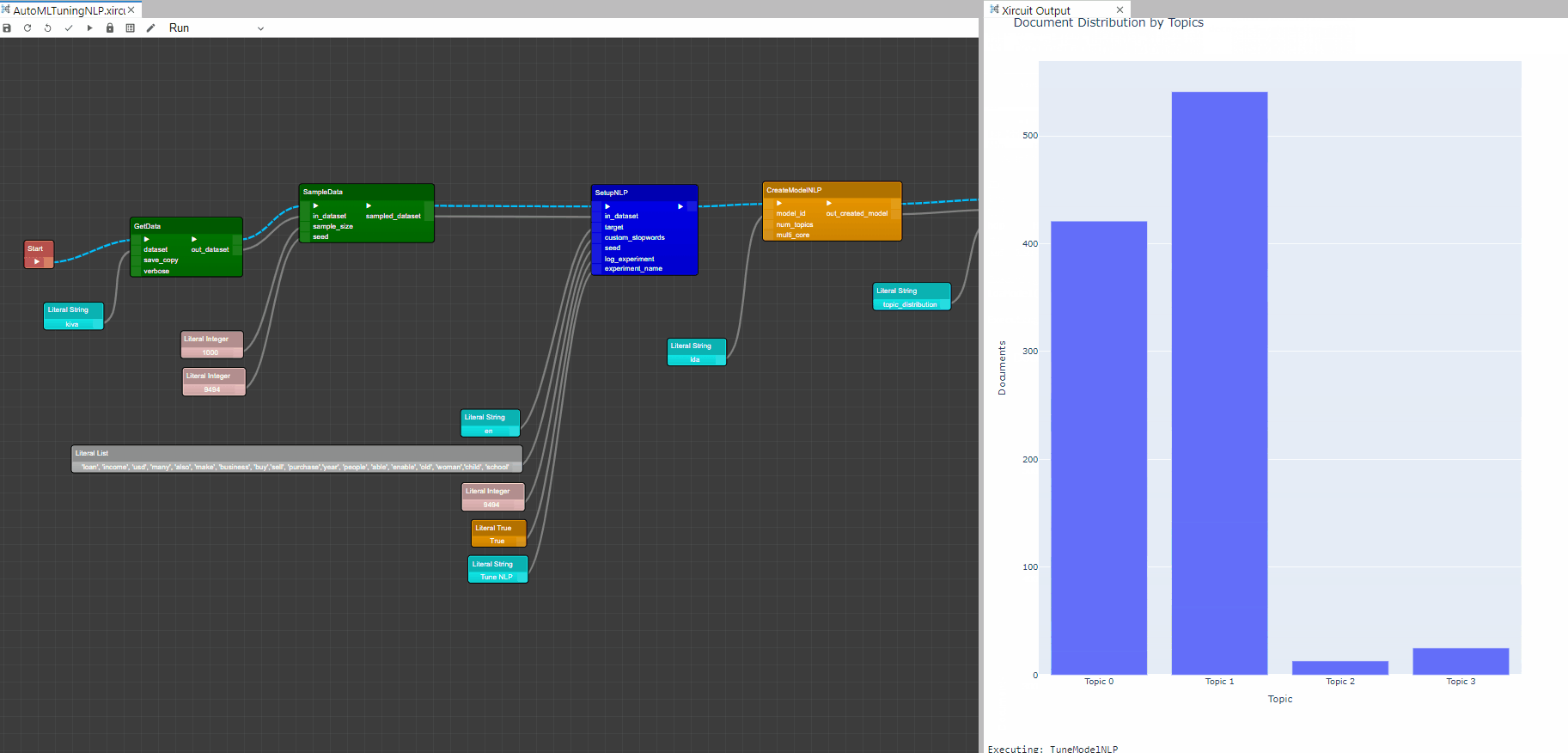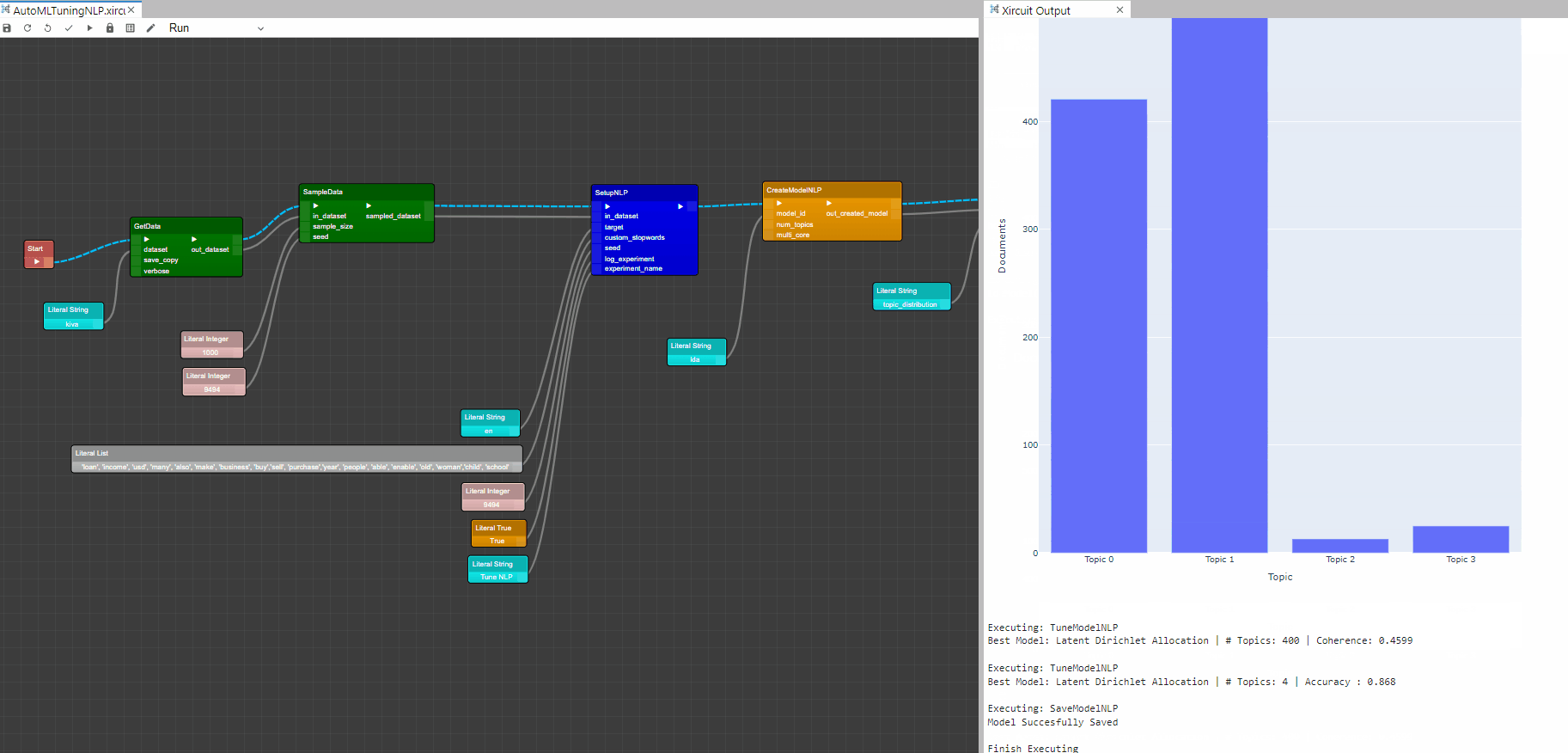
- Tuned NLP model using unsupervised Coherence Value, Topic Coherence measures score a single topic by measuring the degree of semantic similarity between high scoring words in the topic. Using the
TuneModelNLP()component and the Latent Dirichlet Allocation model we apply unsupervised model tuning and get the Coherence Score and num_topics.
Best Model: Latent Dirichlet Allocation | # Topics: 400 | Coherence: 0.4573
- The other method to tune NLP model is by using a classifier or regressor model. In this example, The dataset we are using is labelled using
statuscolumn. In this case we can use theTuneModelNLP()component to determine the best number of topics, since this is a classification problem we used a supervised machine learning approach with Accuracy as measure of interest to get the Accuracy and num_topics.
Best Model: Latent Dirichlet Allocation | # Topics: 8 | Accuracy : 0.869
- Lastly,
SaveModelNLP: This component saves the transformation pipeline and trained model object into the current working directory as a pickle file for later use.