Regression
Before starting any of these examples, please ensure that you installed Pycaret=>2.2 in your working environment. You can use pip install pycaret==2.3.8 to install it too.
Basic Pycaret AutoML Regression
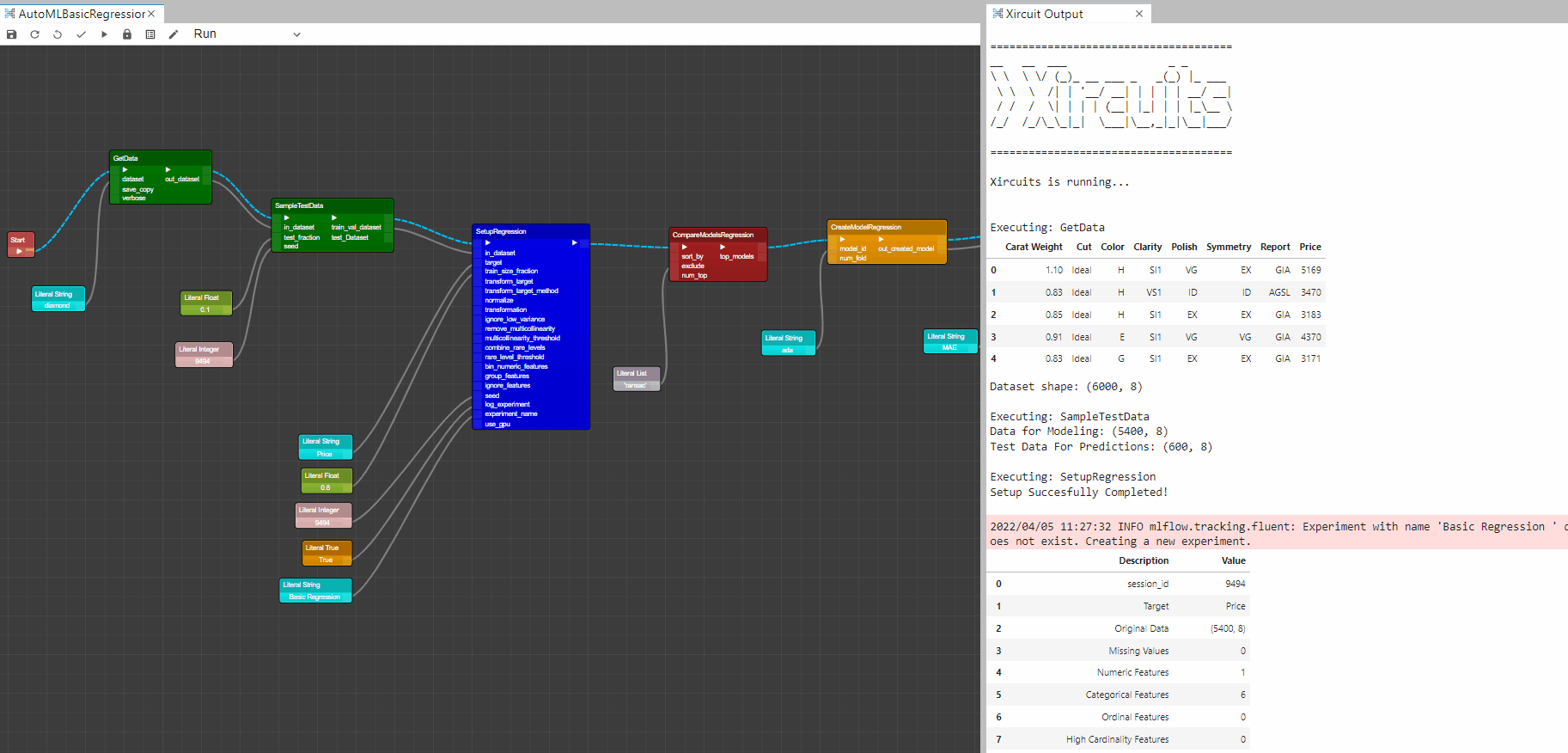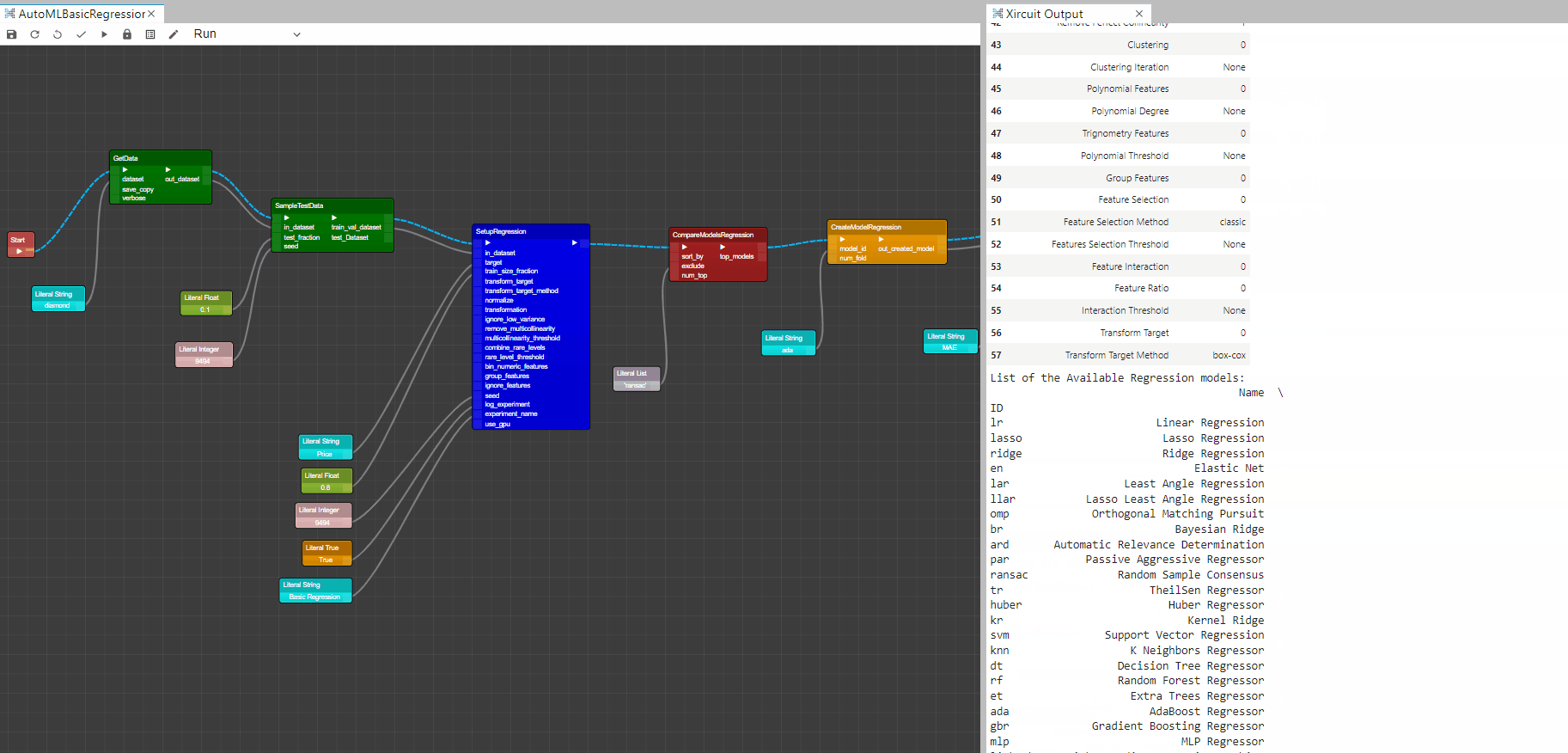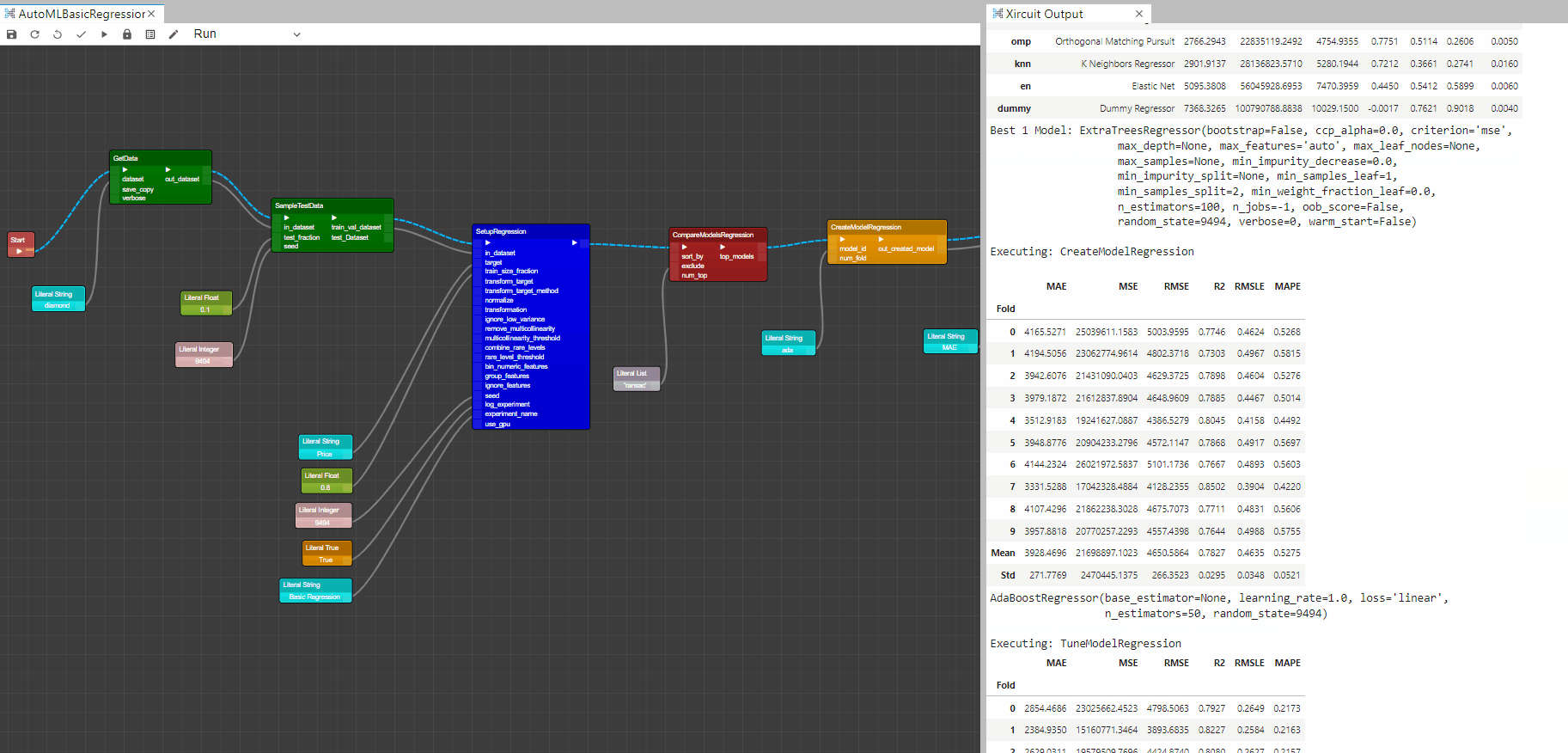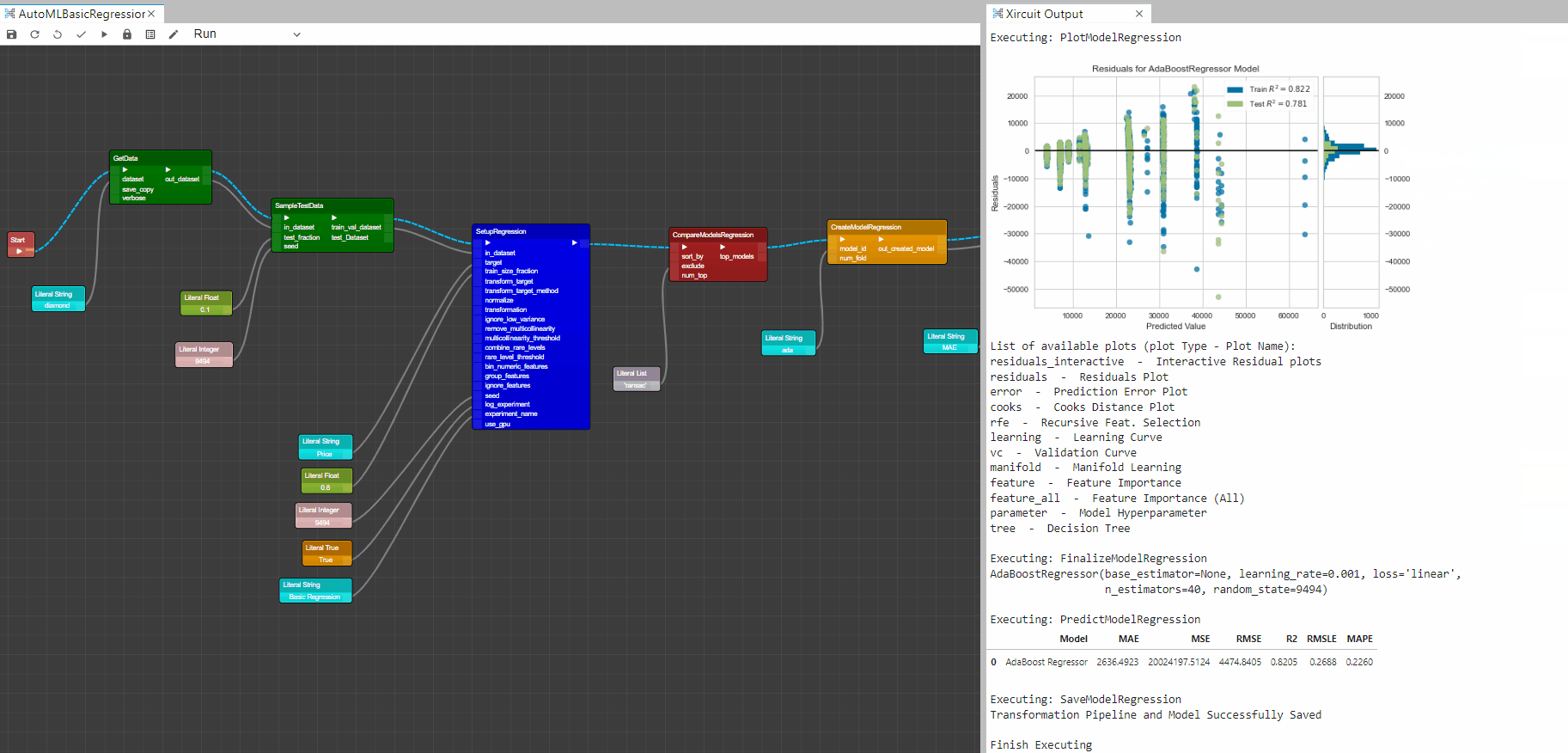
Example: AutoMLBasicRegression.xircuit
In this example, you will learn how to build a basic Pycaret regression application that reads a tabular dataset, setup environment, compare training on multiple ML models, fine-tune models, plot results and save the trained model.
-
To start the workflow,first you will need to get a dataset with
GetData. Here we chose the diamonds dataset. Additionally,SampleTestDatacould be used to set-aside a testing dataset. -
To setup the Pycaret AutoML environment you will need the
SetupRegression. This component initializes the training environment and creates the transformation pipeline.SetupRegressioncomponent must be present before executing any other component. It takes two mandatory parameters: in_dataset and target(label column). All the other parameters are optional. -
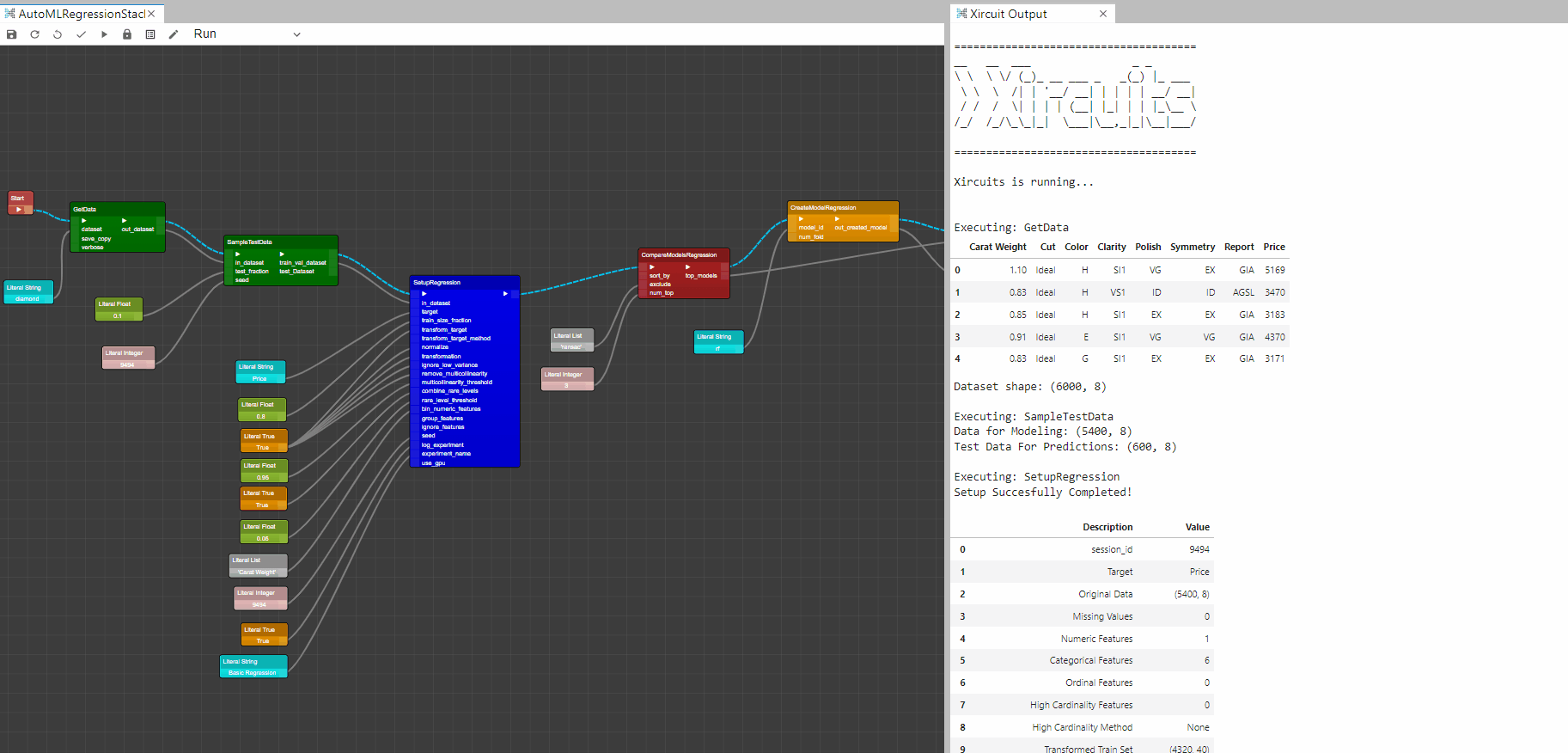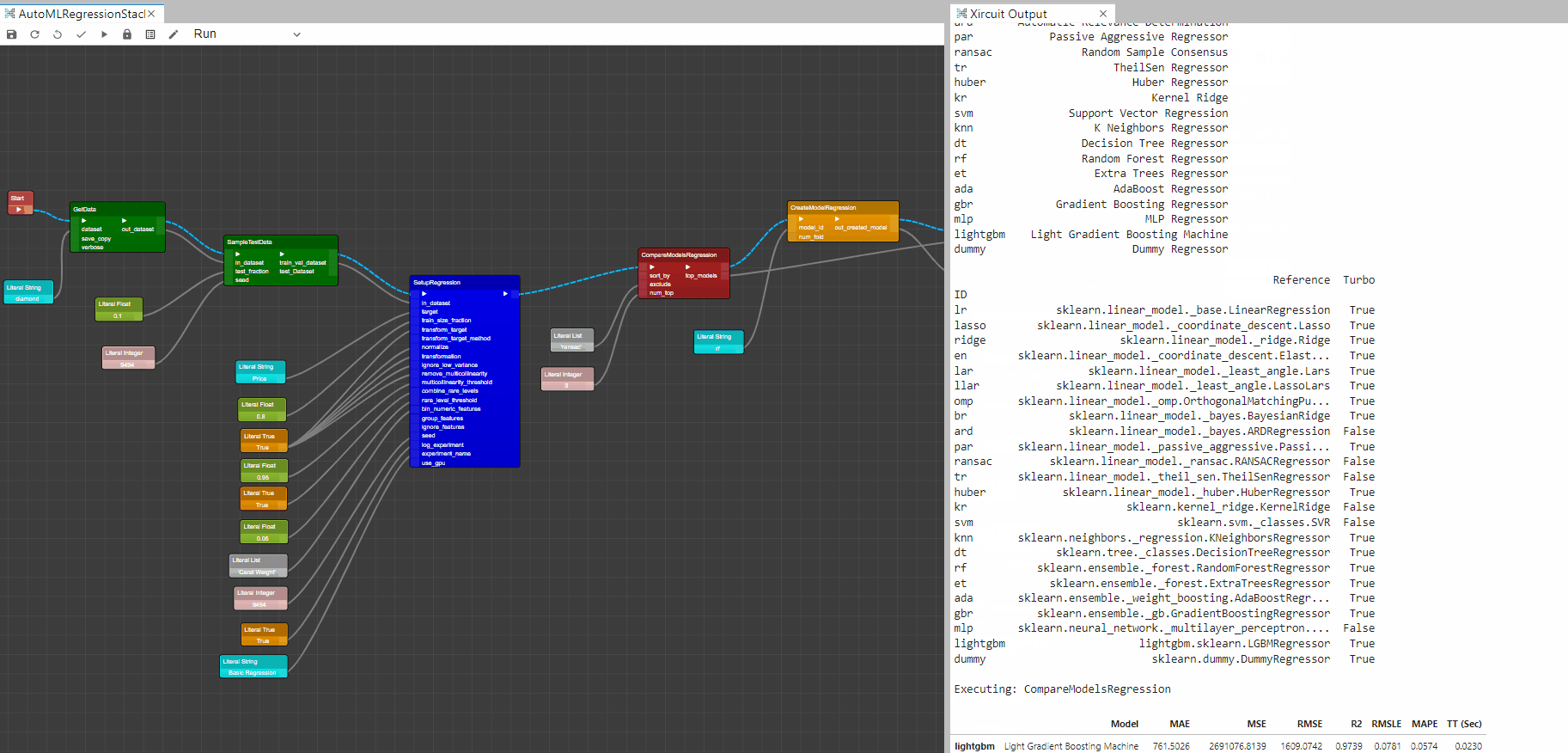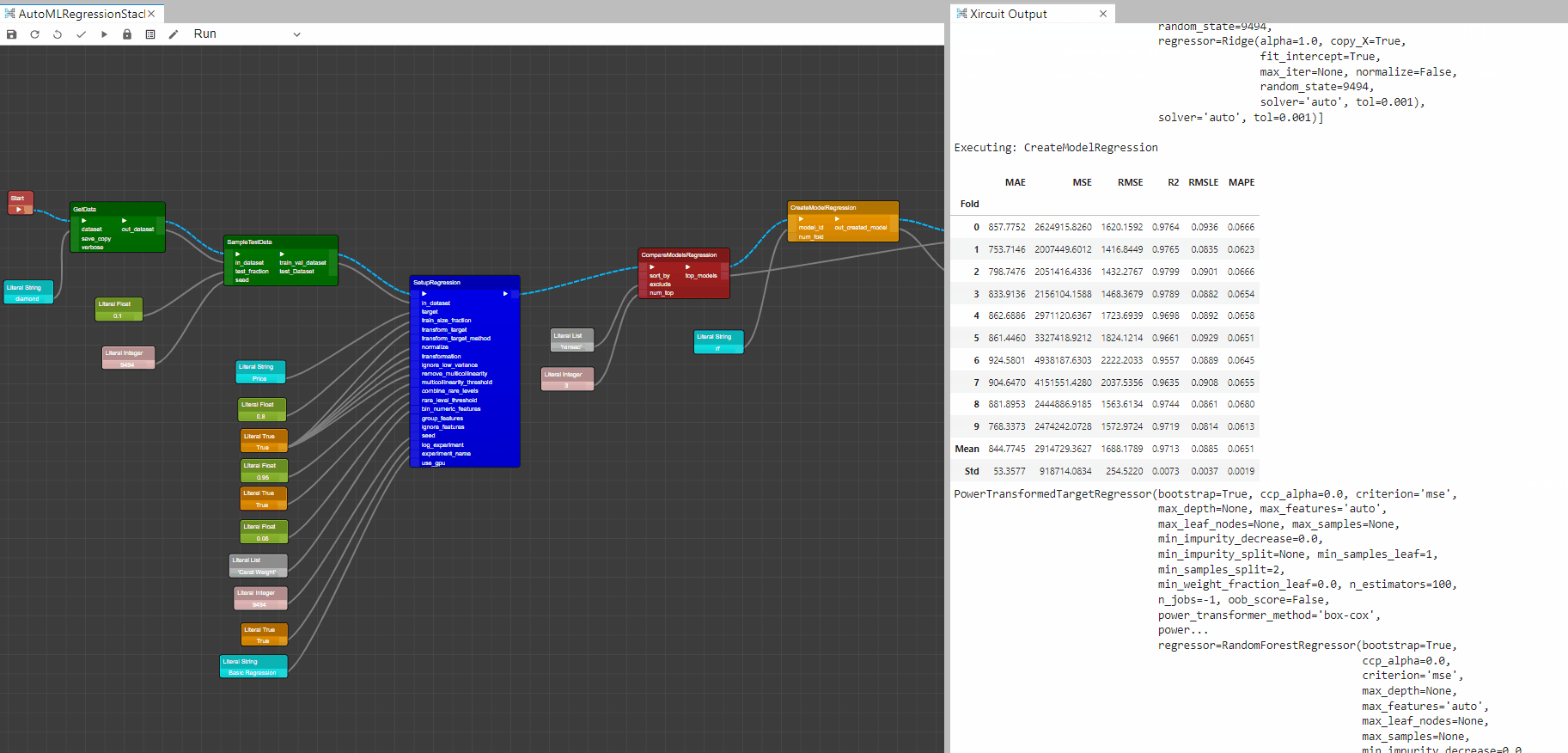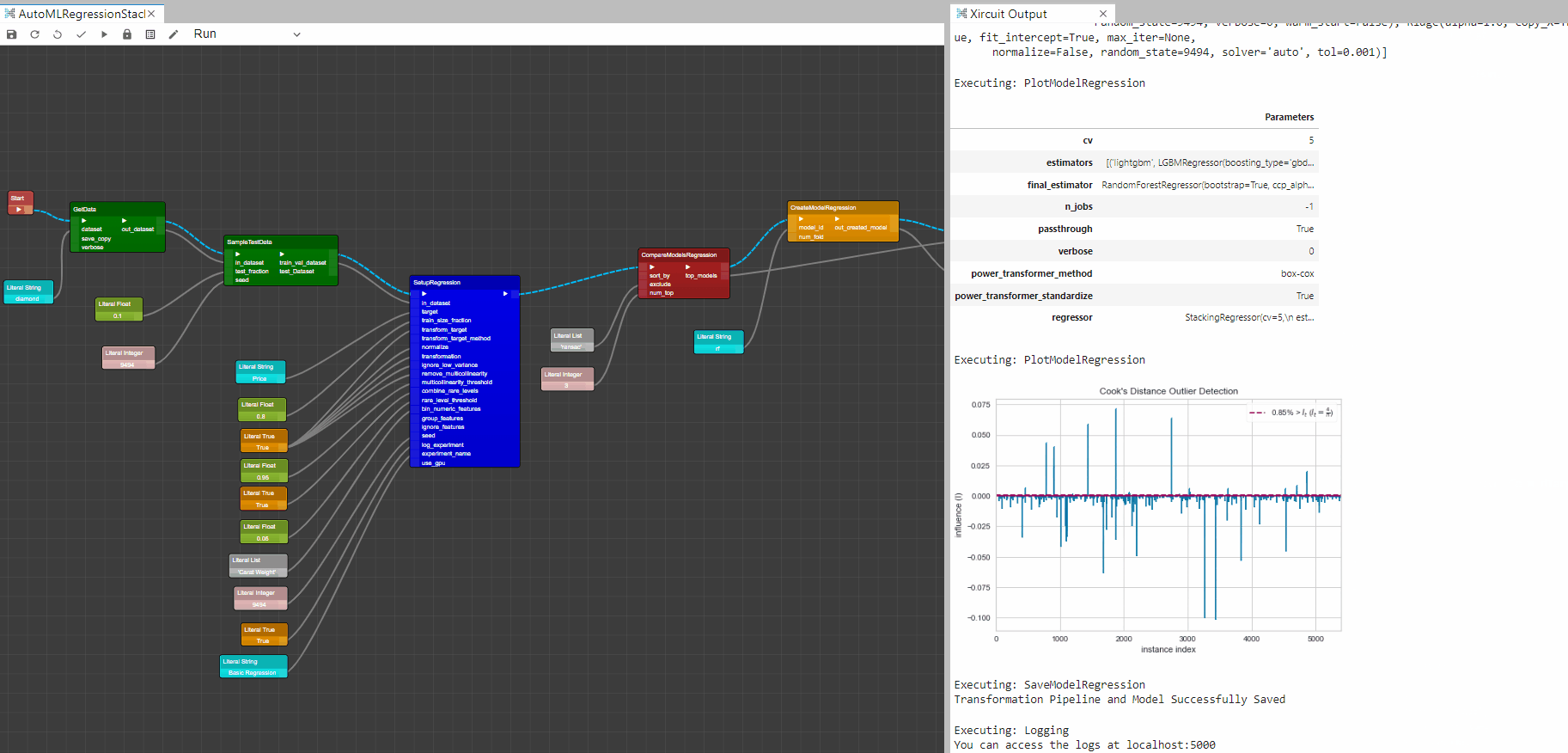
CompareModelsRegression: This component trains and evaluates performance of all estimators available in the model library using cross validation. The output of this component is a score grid with average cross validated scores. Additionally, it outputs a list of the top performing models, number of top model returned can be controlled by the num_top input.
Compare Model Output
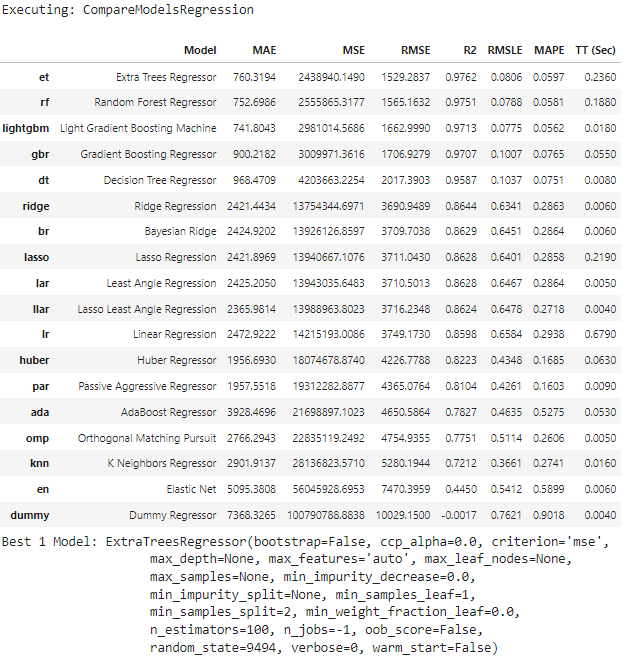
-
CreateModelRegression: This component trains and evaluates the performance of a given model using cross validation. The output of this component is a score grid with CV scores by fold and the created model. -
TuneModelRegression: This component tunes the hyperparameter of a given model, in this case the output model fromCreateModelRegression. The output of this component is a score grid with CV scores by fold of the best selected model based on optimize parameter and the tuned model. -
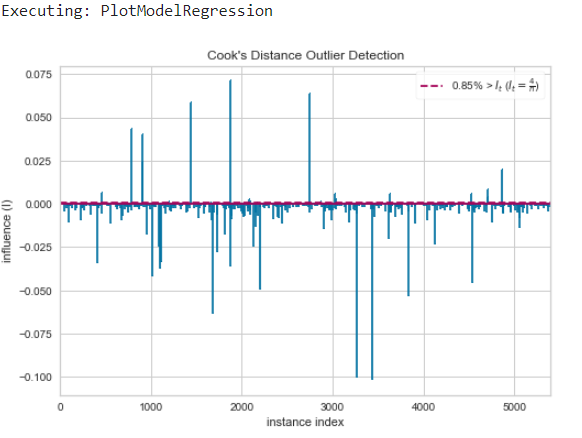
PlotModelRegression: This component analyzes the performance of a trained model on holdout set. The type of the plot desired can be set in plot_type.
Plot Residuals Graph
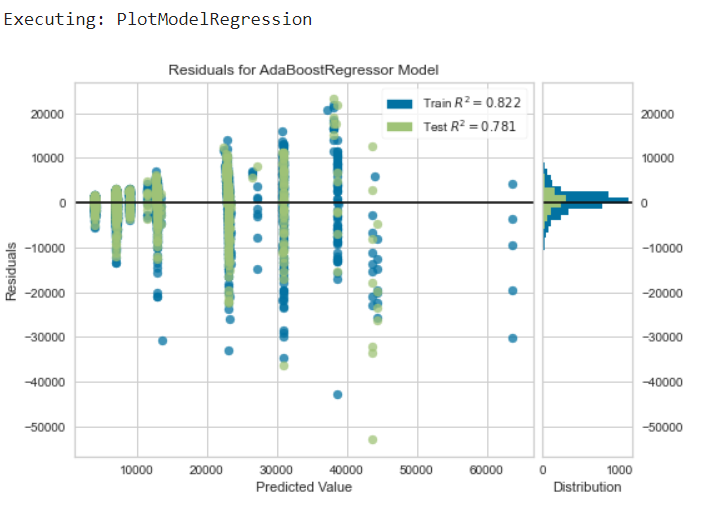
-
PredictModelRegression: This component predicts Label (Regression value) using a trained model. When the predict_dataset input is None, it predicts label and score on the holdout(validation) set. -
FinalizeModelRegression: This component trains a given estimator on the entire dataset including the holdout set. -
AutoMLRegression: This component returns the best model out of all trained models in current session based on the input optimize parameter(default optimize is Accuracy). -
SaveModelRegression: This component saves the transformation pipeline and trained model object into the current working directory as a pickle file for later use.
Pycaret AutoML Model Operation
Example: AutoMLRegressionStackModels.xircuits
In this example, you will learn how to build to apply transformation on the dataset, stack the top performing model, plot, evaluate and save the model.
-
As with the previous example, you would start with a
GetDataandSampleTestData. -
To perform transformation on the dataset you would require to pass parameters to the transformation inputs in
SetupRegression. available dataset transform operation:- transform_target : When set to True, target variable is transformed using the method defined in transform_target_method param. Target transformation is applied separately from feature transformations.
- transform_target_method : Box-cox' and 'yeo-johnson' methods are supported. Box-Cox requires input data to be strictly positive, while Yeo-Johnson supports both positive or negative data.
- normalize : when set to True, it transforms the numeric features by scaling them to a given range.
- transformation : when set to True, it applies the power transform to make data more Gaussian-like.
- ignore_low_variance : When set to True, all categorical features with insignificant variances are removed from the data.
- remove_multicollinearity : When set to True, features with the inter-correlations higher than the defined threshold are removed.
- multicollinearity_threshold :Threshold for correlated features. Ignored when remove_multicollinearity is not True.
- combine_rare_levels : When set to True, frequency percentile for levels in categorical features below a certain threshold is combined into a single level.
- rare_level_threshold : Percentile distribution below which rare categories are combined. Ignored when combine_rare_levels is not True.
- bin_numeric_features : To convert numeric features into categorical,It takes a list of strings with column names that are related.
- group_features : When the dataset contains features with related characteristics, group_features parameter can be used for feature extraction. It takes a list of strings with column names that are related.
More data transformation techniques from Pycaret could be added to the
SetupRegressioncomponent simply by adding new inputs to the component script. -
StackModelsRegression: This component trains a meta model over select estimators passed in the estimator_list parameter. The output of this function is a score grid with CV scores by fold. Here, you could pass a list of top models from theCompareModelsRegressioncomponent or create multiple models and link them to the model_1,model_2,model_3 inputs. -
logging: this component save all the trained models logs to MLflow dashboard can access at localhost:5000, to activate logging you will need to set log_experiment inSetupRegressioncomponent to True.